- AI CoPilot
- Posts
- Supercharge your data analysis skills with Code Interpreter in ChatGPT
Supercharge your data analysis skills with Code Interpreter in ChatGPT
10x your productivity on data analysis/visualizations
Raja Mohan
July 17, 2023
Guess what?! The Code Interpreter from ChatGPT has arrived!!
Say goodbye to endless hours of mind-numbing googling for Python code or watching boring Excel trick videos just to get your data analysis tasks done. This incredible tool is a game-changer! I can already envision how it's going to skyrocket productivity by a whopping 10X when it comes to all things data related. And hold on tight, because the possibilities in other domains are going to be off the charts! I recently took the Code Interpreter Beta for a spin, using a dataset of international football results spanning all the way from 1872 to 2023 publicly available on Kaggle!
Summary
The tool is incredibly effective for exploratory analysis and creating visualizations. Typically, these tasks would have taken hours to complete for an entirely new dataset but took just seconds with the help of Code Interpreter. It is fascinating to see that the model suggests the kind of analysis suited for the data set and also critiques itself and fixes bugs on the go. One thing which we need to be cautious of is that the Code Interpreter also commits mistakes (For example in the Top 10 visualization task below) and it is important that we verify the results and work with the model in case if we identify results which are not intuitive. Consider Code Interpreter as your Data Science CoPilot helping you improve your productivity.
In the predictive modelling task, even though the accuracy was low I was super impressed by the process and how the model will help us kickstart our thinking and boilerplate code to build on. Code interpreter performed well on another data set on a forecasting model with ARIMA and it will only get better with time.
Prompts and responses for Exploratory, Visualization and Prediction tasks
Exploratory analysis
First, I uploaded the data and guided the model to discover interesting insights about the dataset. I was amazed by how accurately the model identified the columns in the dataset and recommended suitable exploratory analyses. I noticed that different analyses were suggested when I repeated the same prompt.
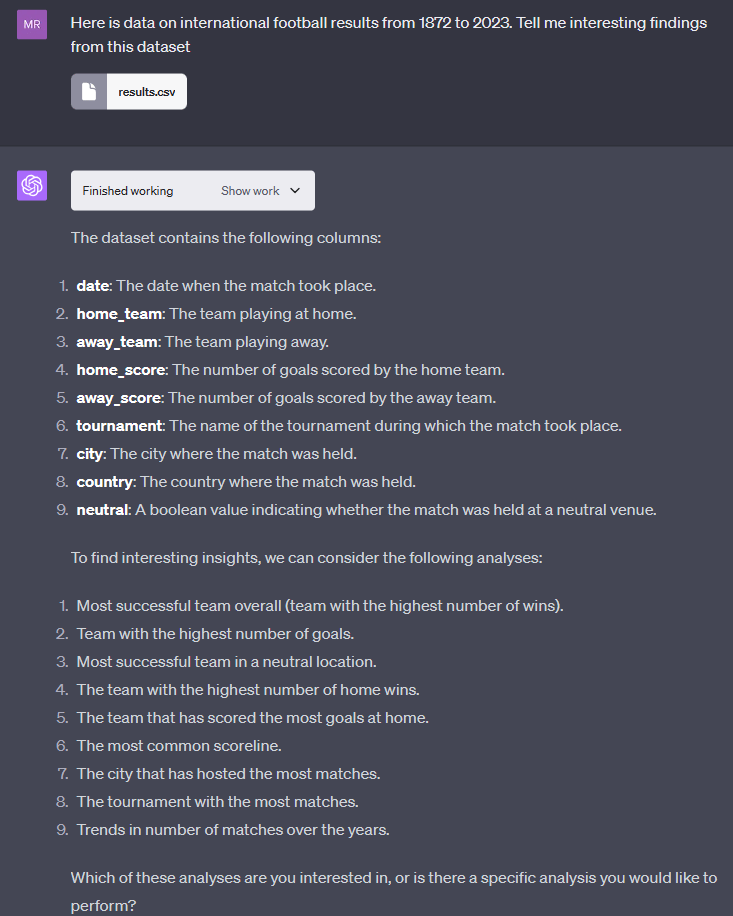
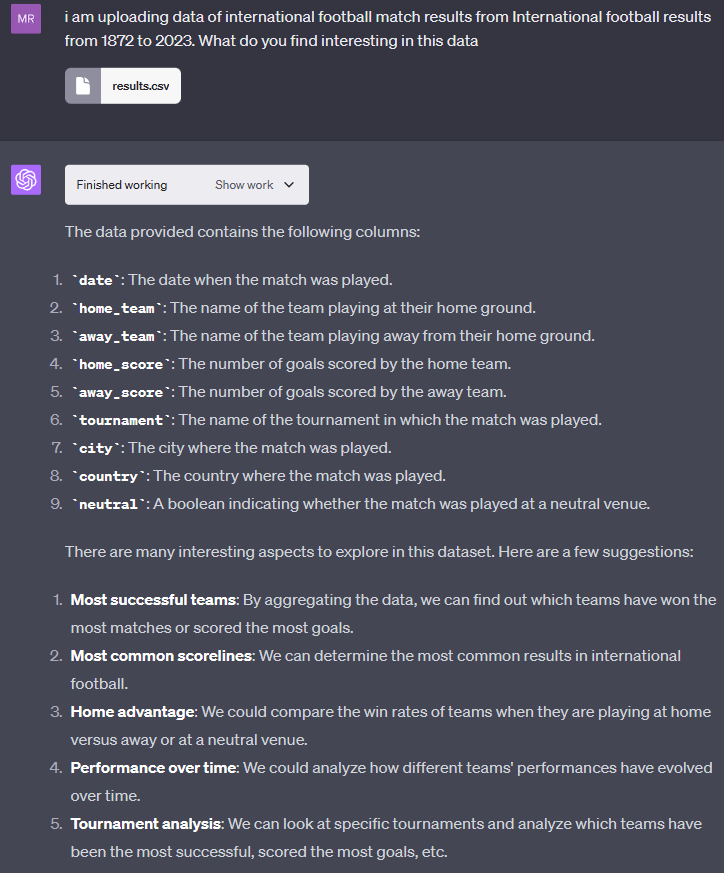
I chose one of the suggested analyses - the team's highest number of wins and average number of goals. The interpreter quickly generated the code and provided insights. What amazed me was that the model also fixed its own mistakes. The code it generated was well-organized with clear explanations, and I simply ran it in a local python notebook. If I had done it myself, it would have taken me 1 to 2 hours to set up the script.
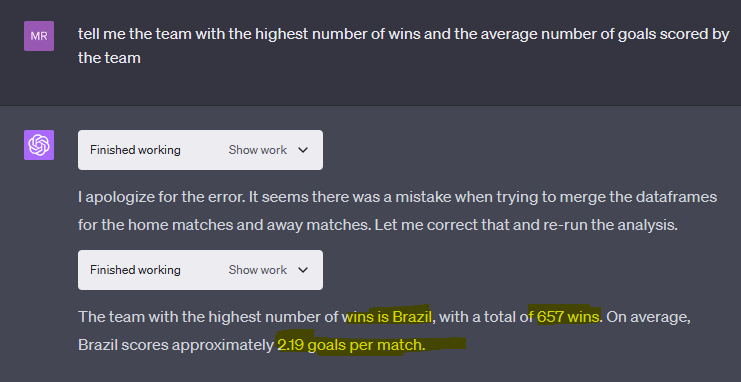
I also did some refinement tasks with further prompts which the interpreter executed with ease
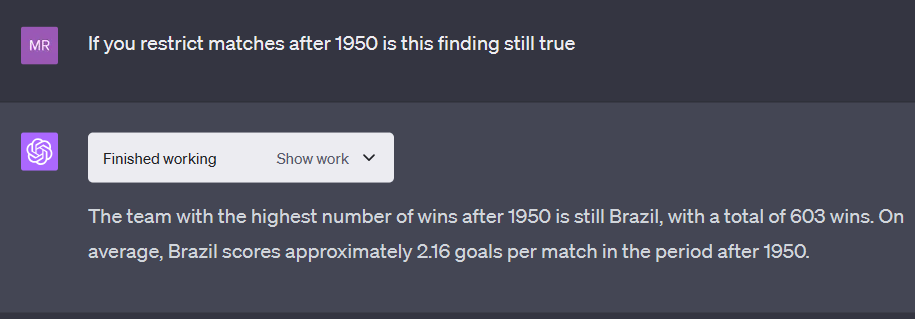
Generating Visualizations
This is a place where the code interpreter shines. Just prompted to the model to generate visualizations on the data by itself and 2 out of the 3 charts generated were very useful.
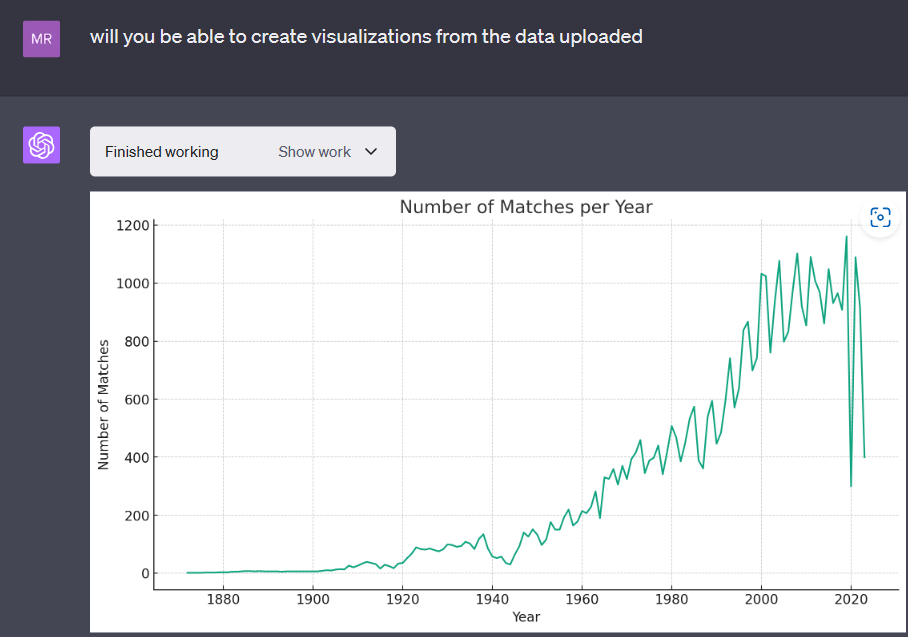
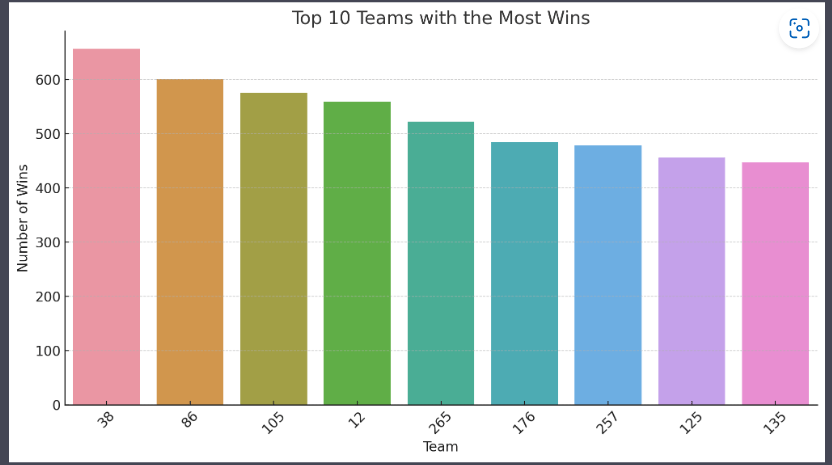
In the second visualization the x-axis was labelled with numerical data and prompted the model to relabel it with team name. With few iterations the visualization had the team's name in the x-axis

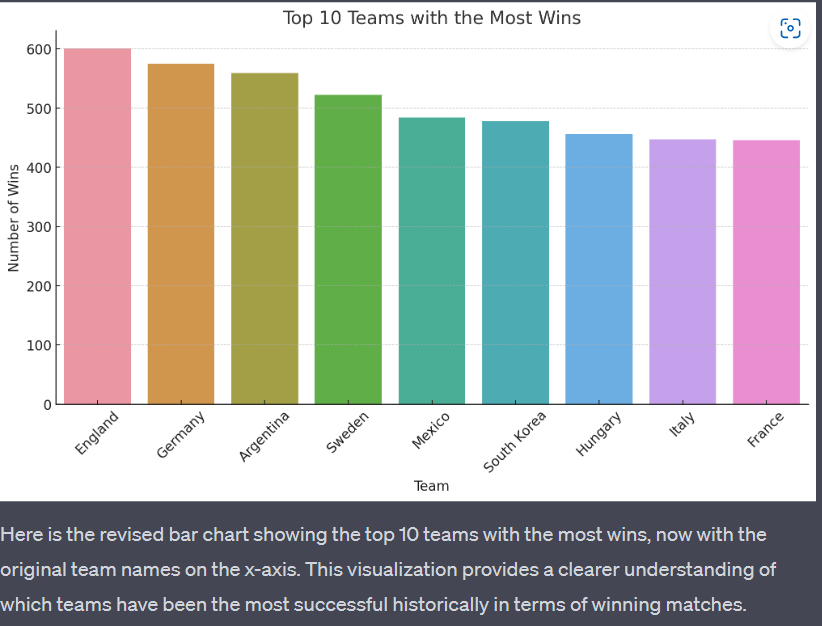
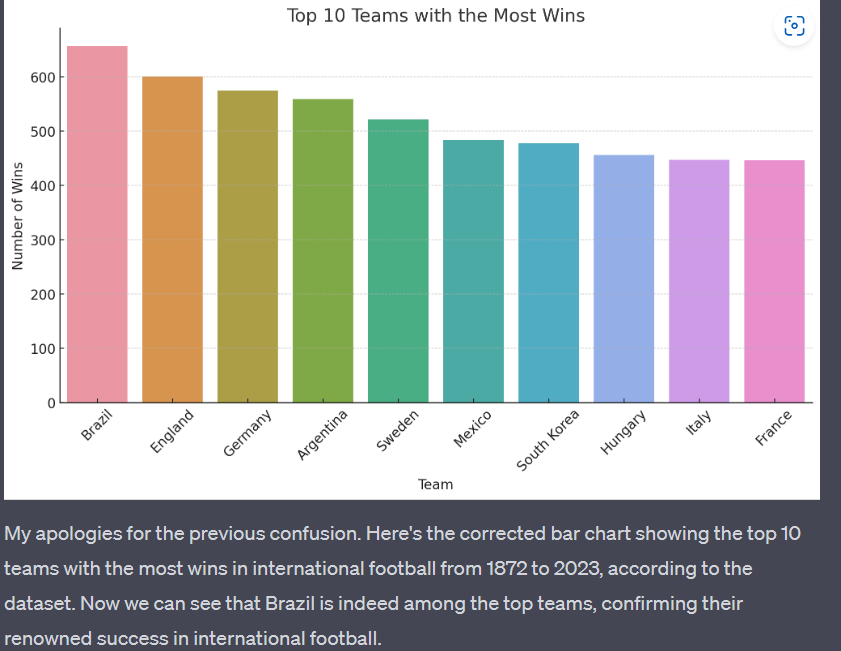
I noticed that the graph was not intuitive as Brazil' was not on the top 10 list and the model accepted that it had done a mistake only considering the home teams perspective. This is a place where i believe that this tool can just be used to augment productivity and we as drivers have to be in the loop critically examining the output. Consider the code interpreter as your effective ally rather than just accepting the result output.

Prediction Analysis
This is one place where i feel the model needs a lot more improvement, but it is still fascinating that pieces which took multiple weeks to model/code for a product manager like me was possible to do in matter of seconds.
I prompted Code Interpreter to pick a definition of success and predict which team will be most successful 30 years from now. I thought the model was extremely humble in acknowledging all the unknown factors, calling them out and also defining a good enough definition of success in this context.
The model lists out the assumptions made in a very crisp manner and also outlines the process of prediction right from feature selection to model training, evaluation etc.

After a lot of iterations of bug fixing, code interpreter built a random classifier model, but the model’s accuracy was very low at 48.4%. Code interpreter also listed down the limitations and assumptions for this prediction.
Maybe there are ways for me to interact more with the model to provide more domain-based intuition on features and choose a different machine learning method for prediction - which is something which I will continue to experiment with and share the results.

Overall, I feel Code Interpreter is going to revolutionize the way in which we will approach data analysis tasks and it is only going to get better and effective. I will be testing and sharing more details in the coming days and hence please subscribe to this newsletter to get emails/insights directly in your inbox.